Quick Background
The system that went down provided “Notices to Air Missions” (NOTAMs), simple text updates about conditions at airports, such as construction, closed runways, landing obstructions, and more. NOTAMs are critical during flight route planning but are not required once an aircraft is airborne.
NOTAM’s Approximate Uptime
The NOTAM system began in 1993, and I could only find one system-wide outage, this one.
Quotes from industry veterans show how rare this is:
“I don’t ever remember the NOTAM system going down like this. I’ve been flying 53 years.” – John Cox, former airline pilot. Source: CBS News - Irina Ivanova
The Timeline
- 8:30 PM ET: Software outage begins.
- FAA’s backup phone system keeps departures going until 7:30 AM ET.
- At 7:30 AM ET, phone lines are overwhelmed → FAA orders ground stop.
- 9:30 AM ET: Software restored.
Over 30 years, there have been 262,968 hours. If we include the backup phone system as part of NOTAM’s uptime, downtime was only about 2.5 hours.
uptime = (262,968 - 2.5) / 262,968 * 100 = 99.999049314%
Look at that 5 nines
That not to say we should brush off the outage. What happen was unacceptable and improvements are needed. But realistically, it will happen again. Like with aviation accidents, we can investigate, fix, and mitigate… but human systems are inherently flawed.
Swish Cheese
There’s a big difference between “Who caused it?” and “Who’s at fault?”
An individual’s actions might have caused the issue, but they may not be at fault, because incidents usually result from a chain of events, much like aviation disasters.
Environmental factors, cultural issues, improper procedures, wrong assumptions, or external pressures can all contribute.
Dr. Reason’s Swiss Cheese Model illustrates this well.
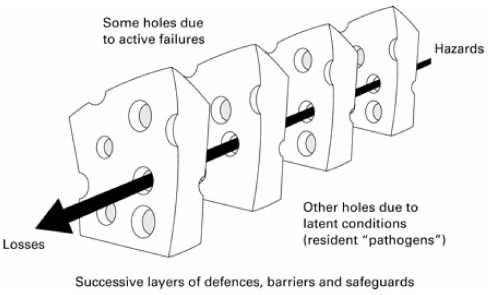
Source: Swiss cheese model by James Reason published in 2000.
Here are the questions I’d ask to understand where the “holes” in the Swiss cheese aligned for this incident:
- Why was the file change done manually? Why wasn’t it automated?
- Is there a test/stage environment for changes?
- Is it maintained like production?
- Is it realistic enough to catch these issues?
- Was the change tested there?
- Yes: Why did it succeed in pre-prod but fail in prod?
- No:
- Was the technician rushed?
- Was it deemed a “simple” change that didn’t need testing?
- Was this a “common” task done often without issue?
- If no production-like environment exists:
- How are changes tested?
- Is cost the reason for no test environment?
- Was there one in the past?
- If the backup was a day old:
- What’s the backup cadence?
- How often is the restore process verified?
- Were proper procedures followed?
- Yes: What should be added so this doesn’t happen again?
- No:
- How often has this type of work been done without following procedure?
- How many others have done the same without issue?
- Is there a culture of Normalized Deviance that made the action seem “normal”?
A Humbling Reminder of Centralized Systems
This was a humbling reminder of the fragility of modern life’s dependencies on software systems.
A single person’s action, even a single keystroke, can affect millions.
It’s a reminder that in my own work, the software systems I build and maintain can directly impact clients and a small actions can have outsized effects.